
Where configuration management falls short: model-driven OpenStack

Tytus Kurek
on 2 September 2021
Tags: Charms , Juju , Model-driven operations , OpenStack , Private cloud
Have you ever installed OpenStack from scratch? I know, it sounds geeky, unnecessary and maybe even overcomplicated … It is after all 2021, OpenStack is mature, there are hundreds of OpenStack distributions available out there, configuration management tools are all the way around and installing OpenStack from scratch almost sounds like compiling the Linux kernel or using make scripts to install software on Ubuntu. I went through this process, however, back in 2014 when I was first learning OpenStack. That was long before I got to know model-driven OpenStack.
I set up physical nodes in my lab environment. I put Ubuntu on them. Then I installed all supporting services, including the SQL database and the message broker. And then, basically, for each OpenStack service, I was creating databases, creating identities in Keystone, installing packages and adjusting configuration files. When I finally finished this exercise two months later I had my first instance running on OpenStack, a few grey hairs and a well-formed opinion about OpenStack: it is super complex!
Where configuration management falls short
I know, this is just an opinion. But read the below and judge for yourself. OpenStack has 29 official services, around 80 configuration files and around 5,000 options inside of those files. Who knows them all and can call themselves an OpenStack expert? Definitely not me.
But wait a second. Isn’t it something that configuration management was expected to solve? After all, you can just install Ansible, SaltStack or any other configuration management tool, set up hosts, roles, playbooks, etc. and you are done, aren’t you? Apparently so, but the introduction of automation does not really eliminate the complexity, right? You still have to know what exactly to put inside of your code. I know, there are a lot of existing playbooks for OpenStack available out there. The OpenStack community even established an official OpenStack-Ansible project exactly for this purpose. But don’t forget that database and configuration file schemas often change between OpenStack releases, so this code is never static. Finally, think about common day-2 operations, such as OpenStack upgrades? Does your configuration management software support them? And even more importantly, what about the repeatability and reusability of your automation code?

Basic facts about OpenStack
So is OpenStack really as black as it is painted? Let’s look around and try to evaluate that. Here are some basic facts about OpenStack:
- Its combined market size worldwide reaches $4.5B in 2021 and is expected to grow at the compound annual growth rate (CAGR) of 29% in the following years.
- It is the most widely used open source private cloud platform and its adoption has been constantly growing for the last few years.
- It is one of the three biggest open source projects on the planet.
- OpenStack is a mature project celebrating its 10-year anniversary in 2020.
In fact, leading telcos, financial institutions, hardware manufacturers, government institutions and enterprises have been using OpenStack in production for years. How did they manage to deal with its complexity then? Well, this is where model-driven OpenStack comes in.
What is model-driven OpenStack?
Imagine that the OpenStack deployment and operations look as follows. First, you define what your cloud is going to look like. You decide which services it is going to consist of (Keystone, Glance, Nova, etc.), select the number of service units depending on your high availability requirements and place those units across physical nodes in your data centre. Then you draw integration lines between services that should talk to each other and define high-level configuration parameters depending on your requirements. This is what we call an OpenStack model.
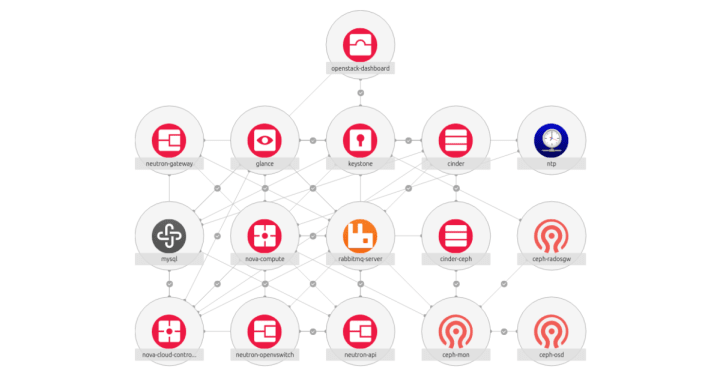
But this is just the beginning. You run a single command and OpenStack gets deployed and configured according to your model. Need to add a new service? You add it to the model and again, it gets deployed automatically. Need to scale the cluster out? Guess what, you update the model to include more service units or physical nodes. And how about day-2 operations? No, don’t touch the cloud! Just interact with the model instead. Simply run the desired action and see the entire procedure being orchestrated accordingly.
How is it possible? Well, this is where the power of the model-driven paradigm comes in. Model-driven OpenStack uses the concept of charms which are operations software packages. They encapsulate common day-1 and day-2 procedures, enabling fully automated installation, operations and integration of applications with other software components. Behind charms, there is a tool called Juju which maintains the current application topology (the model) and orchestrates the execution of the charms’ code based on what is currently defined in the model.
Model-driven OpenStack in action
Now, once you know what model-driven OpenStack is, let’s have a look at it in action. In the following example, we’re going to deploy a simple OpenStack cluster consisting of the database, Keystone and Horizon, and backup Keystone database using the model-driven paradigm. This example assumes the Juju environment has already been set up on an Ubuntu 20.04 LTS machine with a local LXD provider according to the official Juju documentation.
First, let’s create a model for our OpenStack deployment:
$ juju add-model openstackNow deploy one unit of each service:
$ juju deploy percona-cluster
$ juju deploy keystone
$ juju deploy openstack-dashboardThen establish integrations between applications that should talk to each other:
$ juju relate percona-cluster:shared-db keystone:shared-db
$ juju relate keystone:identity-service openstack-dashboard:identity-serviceFinally, set the password for the `admin` user:
$ juju config keystone admin-password="admin"Now, once everything gets deployed, you can log in to the Horizon dashboard at the IP address of its LXD container that you can find by running the following command:
$ juju status | grep dashboard | tail -n 1 | awk '{print $5}'Make sure you append /horizon to the URL and fill in the login form accordingly:

Finally, you shall be able to see the Horizon dashboard (you can navigate through the menu on the left):

Now, if you want to backup the Keystone database, simply run the following command:
$ juju run-action percona-cluster/0 backup --waitThat’s it. Juju has just backed up the database for you.
But wait a second! Where are Glance, Nova, Neutron and Cinder in the Horizon dashboard? Well, you have to add them to the model, remember? Try to do it yourself as the next step in your adventure with model-driven OpenStack.
Learn more
Our community members appreciate the power of the model-driven paradigm once they start using it in practice. Why don’t you try it and see for yourself?
Get model-driven OpenStack up and running in your lab environment and benefit from high-level abstraction and full automation. Refer to our OpenStack Deployment Guide whitepaper if you get lost.
Visit the Juju website to learn more about the model-driven paradigm in general. You can also browse Charmhub to get access to charms for hundreds of common open source applications, including Kubernetes, Kubeflow, Observability stack, etc.
Microcloud. Same great performance.
Deploy highly available, secure, and dense microcloud environments anywhere, with a lightweight cloud infrastructure that’s designed for the edge.
Newsletter signup
Related posts
Deploy your Spring Boot application to production
In this article we walk through the steps required to deploy a Spring Boot application to production using Juju and Kubernetes. The goal is to showcase the...
OpenStack cloud – happy 15th anniversary!
Happy birthday, OpenStack! It’s astonishing how fast time flies – fifteen years already. Yet, here we are: OpenStack cloud still stands as a de facto standard...
OpenStack PoC? No problem!
Setting up a proof of concept (PoC) environment is often one of the first steps in any IT project. It helps organizations to get to grips with the technology,...